Streaming Data and Entropy
Streaming Data
- Stream data, a potentially unbounded(infinite size), ever-growing dataset
- Volume, Velocity (Variety)
- Too large for single memory
- Too fast for single CPU
- Too changeable for single machine learning system
- Volume, Velocity (Variety)
| Stream Data and Processing | Traditional Data and Processing |
|---|---|
| Online/Real-time processing | Offline processing |
| Linear and sub-linear computational techniques are widely used | Techniques with high space and time complexity are used if necessary |
| Limitation on access times and process times for each instances | The restrictions are more loose |
| Storage of all data is not feasible | Storage of data is feasible |
| Store statistic, temporary, processed data | Storage of the raw data is possible |
| Approximate results are acceptable | Accurate results are required |
| Processing of samples of data is the usual task | Processing of every data item/record is the usual task |
| Statistical characteristics change over time | Statistical characteristics are stable |
Concept Drift
- Concept drift, The nature of data may evolve over time due to various conditions
- The number and relevance of instances and features may change by drifting
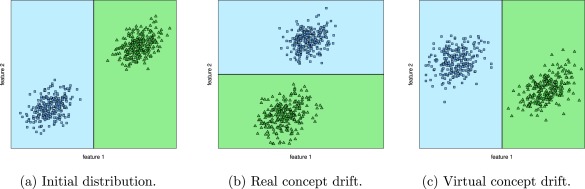
- Different influence on the learned classification boundaries
- Real concept drift
- Virtual concept drift
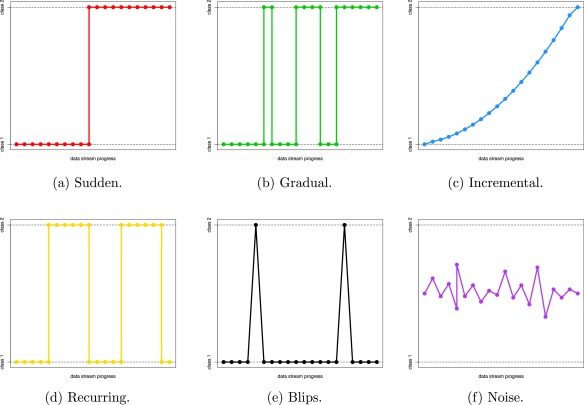
- Types of change
- Sudden
- Gradual
- Incremental
- Recurring
- Blips
- Noise
- Mixed, more than one types
Tackling Drifting
- Concept drift detector
- Explicit drift handling
- Statistical criteria
- SD
- Predictive error
- Instance distribution
- Stability
- Two stages
- When drifting occurs, train a new classifier on recent instances
- When drifting is severe, replace the old classifier with the new one
- Sliding windows
- Implicit drift handling
- Windows size is critical
- Online learner
- Each object only be processed once
- Ensemble learner
Concept Evolution
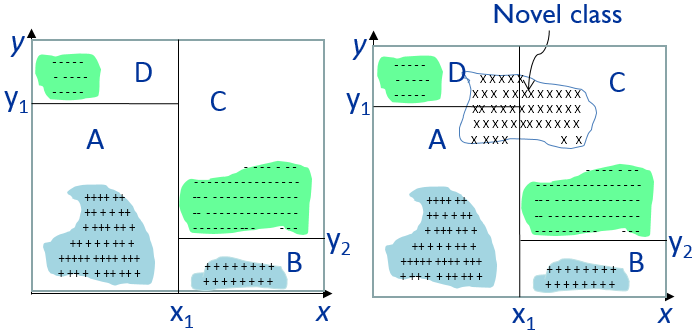
- New classes evolve in the data
- Solutions
- Radius and adaptive threshold
- Gini Coefficient
- Multiple novel class detection
Evaluation Criteria
- Predictive power
- Memory consumption
- Recovery time
- The time about accommodating new instances and updating algorithm structure
- Process instances before new ones will arrive to avoid queuing
- Decision time
- Requirement for true class labels
- Hard to label the entire data stream
Data Processing
Instance Reduction
- Sampling
- Instance Selection (IS)
- New concept may be classified as noise and removed by a misbehavior
- Instance Generation (IG)
Dimensionality Reduction
- Feature Selection (FS)
- Filter
- Easily adaptable to the online environment
- Hard to deal new features or classes
- Wrapper
- Hybrid
- Filter
- Feature loss
- Lossy Fixed (Lossy-F)
- Fixed feature space
- Lossy Local (Lossy-L)
- Feature space varies with training batch
- Feature space of training data may be different with test data
- Lossless Homogenizing (Lossless)
- Unify train/test feature space
- Pad missing features
- Lossy Fixed (Lossy-F)
Feature Space Simplification
- Normalization
- Discretization
- Bins
- bins
- Size\boundaries of bins
- Bins
Entropy
Shannon Entropy
Generalized Entropy
- Control the tradeoff between contributions from the main mass of the distribution and the tail
Rényi Entropy
Tsallis Entropy
Comparison by Binominal Distribution
- , probability of success
- , probability of failure
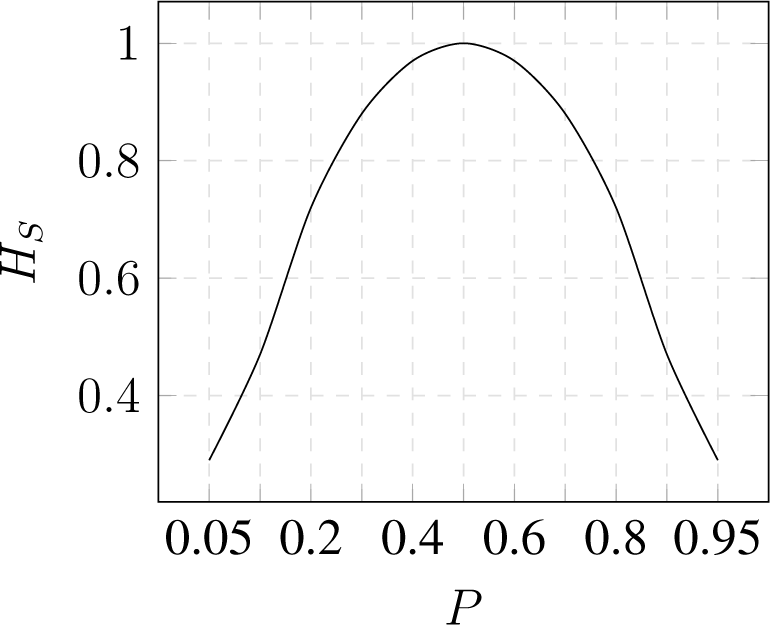
Shannon entropy
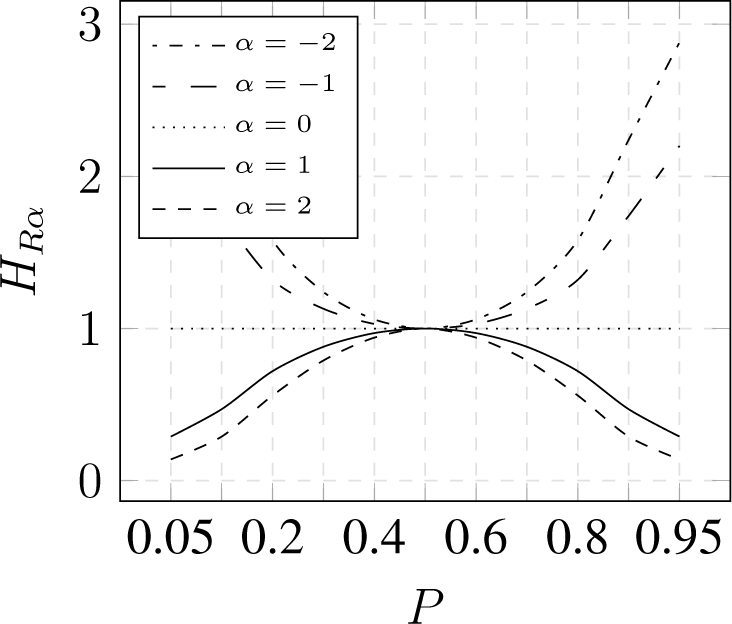
Rényi entropy of several -values
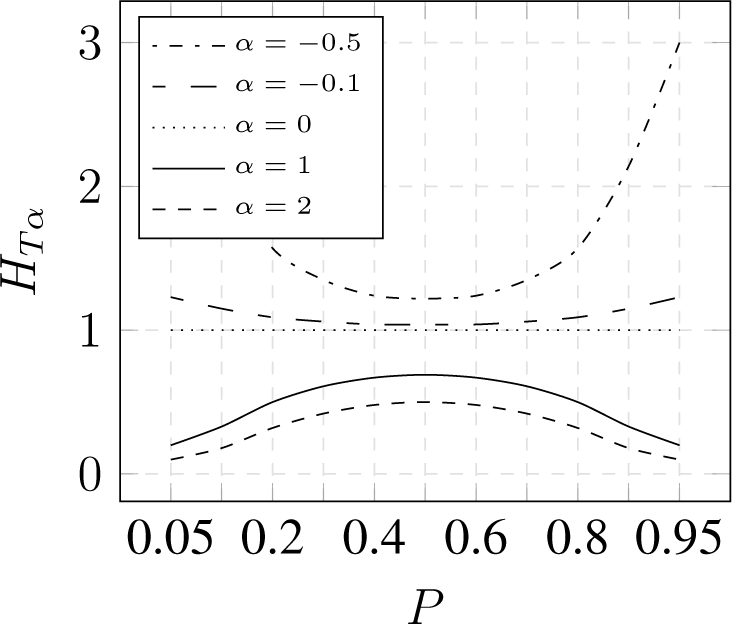
Tsallis entropy of several -values
References and Recommended Readings
- Data Stream Algorithms Intro, Sampling, Entropy
- Data Stream Mining
- A survey on data preprocessing for data stream mining: Current status and future directions
- Classification and Novel Class Detection of Data Streams in a Dynamic Feature Space
- Data Stream Mining, Data Mining and Knowledge Discovery Handbook
- An Entropy-Based Network Anomaly Detection Method
- Rényi entropy, wikipedia
- Shannon entropy in the context of machine learning and AI
- WELCOME TO THE ENTROPY ZOO, Beyond i.i.d. in information theory
- Philippe Faist, The Entropy Zoo